Amazon Redshift Architecture
Amazon Redshift follows a master-slave architecture, consisting of a leader node and multiple compute nodes.
- Leader Node: The leader node acts as a bridge between client applications and compute nodes. It parses queries, develops execution plans, and coordinates the execution of queries across compute nodes.
- Compute Nodes: Compute nodes execute the queries and store data. Each compute node has its own dedicated CPU, memory, and disk storage. Compute nodes are partitioned into slices, with each slice having its own resources.
Node Types
Amazon Redshift offers two types of nodes:
- DC2 Nodes: These are dense compute nodes that use local SSD storage. They are ideal for workloads that require high performance and low latency.
- RA3 Nodes: These nodes decouple compute and storage, allowing you to scale storage independently. RA3 nodes use SSD for hot data and S3 for cold data, providing a cost-effective solution for large datasets.
Redshift Spectrum
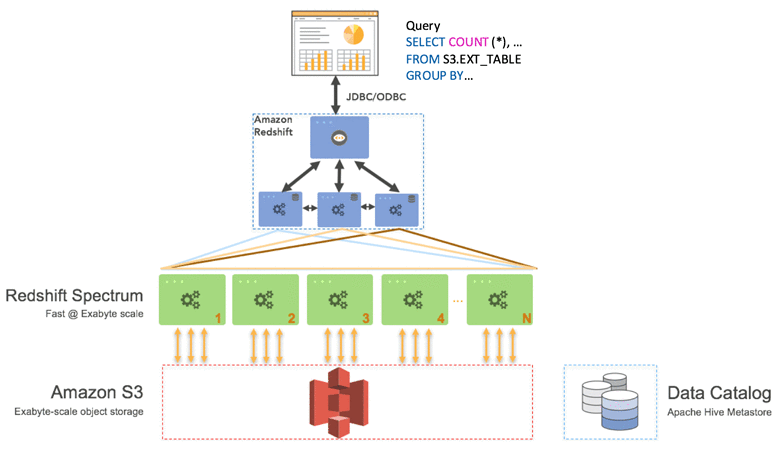
Redshift Spectrum is a feature that allows you to query data directly from Amazon S3 without loading it into Redshift. This enables you to analyze exabytes of data in your data lake alongside the data in your Redshift data warehouse. Redshift Spectrum separates storage and compute, allowing you to scale your queries independently.
Use Cases for Amazon Redshift
- Accelerating Analytics Workloads: Redshift is ideal for running complex analytical queries on large datasets.
- Modernizing On-Premise Data Warehouses: Redshift provides a cost-effective and scalable alternative to traditional on-premise data warehouses.
- Unified Data Warehouse and Data Lake: With Redshift Spectrum, you can analyze data across your data warehouse and data lake using a single service.
Redshift Durability and Backup
Amazon Redshift ensures data durability by maintaining three copies of your data within the cluster and backing up data to Amazon S3. Failed drives or nodes are automatically replaced, ensuring high availability and reliability.
Redshift Distribution Styles
Redshift offers several distribution styles to optimize data storage and query performance:
- Auto: Redshift automatically determines the best distribution style based on the size of the data and other factors.
- Even: Rows are distributed evenly across slices in a round-robin fashion.
- Key: Data is distributed based on a specific column, similar to bucketing.
- ALL: The entire table is copied to every node, useful for small tables that are frequently joined.
Redshift Sort Keys
Sort keys in Redshift determine the order in which rows are stored on disk. By designating a column as the sort key, you can improve query performance for filtering, searching, and joining operations.
Loading Data into Redshift
You can load data into Redshift from Amazon S3 using the COPY command. The COPY command allows you to load data from S3 into a Redshift table, while the UNLOAD command allows you to export data from Redshift to S3.
Example: Loading Data from S3 to Redshift
- Create a Redshift Table:
CREATE TABLE retail_db.sales.orders (
order_id INTEGER,
order_date VARCHAR(100),
order_customer_id INTEGER,
order_status VARCHAR(30)
);2. Copy Data from S3:
COPY retail_db.sales.orders
FROM 's3://tt-redshift-demo/retail-data/orders'
IAM_ROLE 'arn:aws:iam::982081092057:role/service-role/AmazonRedshift-CommandsAccessRole-20241105T185810'
FORMAT AS CSV DELIMITER ','
IGNOREHEADER 1
REGION 'us-east-1';Amazon Redshift is a powerful, scalable, and cost-effective data warehousing solution that addresses the limitations of traditional on-premise data warehouses. With its advanced features like Redshift Spectrum and Serverless, Redshift enables you to analyze data across your data warehouse and data lake seamlessly. Whether you’re looking to accelerate your analytics workloads or modernize your data infrastructure, Amazon Redshift is a compelling choice.
By understanding the architecture, benefits, and use cases of Amazon Redshift, you can leverage its full potential to drive insights from your data and make informed business decisions.
please see the blog on Redshift Serverless.