
In today’s data-driven era, businesses and organizations deal with unprecedented amounts of data. This explosion of information, known as Big Data, has redefined how data is processed, analyzed, and leveraged for decision-making. But what exactly qualifies as Big Data, and why do traditional systems fall short in handling it? Let’s explore the defining characteristics of Big Data and the technological advancements that enable its management.
What is Big Data?
While informal definitions of Big Data often emphasize its sheer size, IBM formalizes the concept by identifying five defining characteristics, commonly referred to as the 5Vs of Big Data: Volume, Variety, Velocity, Veracity, and Value.
1. Volume
Big Data involves massive amounts of information that cannot be processed or stored on a single computing system. This volume of data often spans terabytes to petabytes and originates from diverse sources, such as:
- Social media activity
- Internet of Things (IoT) sensors
- E-commerce platforms
Example: A social media platform like Twitter generates petabytes of data daily, including tweets, images, and videos.
2. Variety
Data exists in multiple formats, requiring tailored processing methods.
- Structured Data: Stored in a predefined format, such as relational database tables with rows and columns.
Example: Employee records in a MySQL database. - Semi-Structured Data: Contains a partial schema but does not conform to a rigid structure.
Example: JSON and XML files. - Unstructured Data: Has no schema and includes data types like images, videos, and log files.
Example: Security camera footage or customer service chat logs.
3. Velocity
Big Data is not just about size; it’s also about speed. Velocity refers to the rapid generation and processing of data streams in real-time.
Example: During a flash sale on Amazon, the system must track and analyze millions of transactions in real-time to identify key metrics, such as how many iPhones were sold in the last hour.
4. Veracity
The quality of data is a critical challenge. Data can be incomplete, inconsistent, or noisy. Effective Big Data systems are designed to handle and cleanse imperfect data to extract reliable insights.
5. Value
Ultimately, the purpose of processing Big Data is to derive value. Insights extracted from large datasets drive strategic decisions, enabling businesses to optimize operations and uncover opportunities.
The Need for a New Technological Approach
Traditional computing systems, often referred to as monolithic systems, are insufficient for handling Big Data. To understand this limitation, we must compare monolithic and distributed systems.
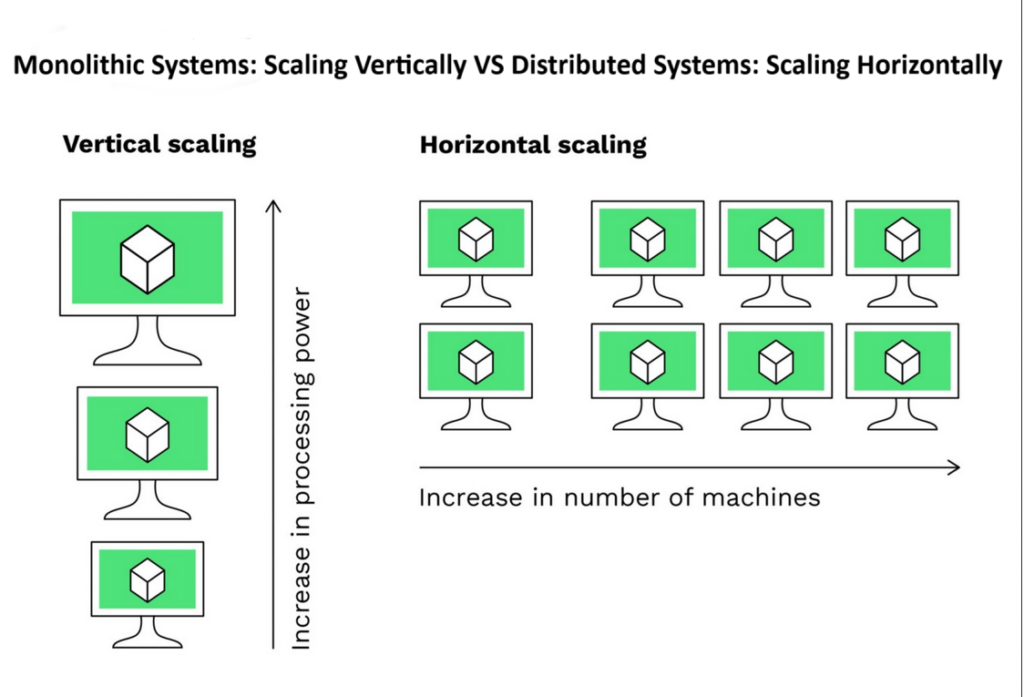
Monolithic Systems: Scaling Vertically
A monolithic system is a single large machine with significant resources like CPU cores, RAM, and storage. While adding more resources (vertical scaling) can improve performance initially, the benefits diminish over time due to hardware limitations.
- Example: Doubling resources (e.g., from 4 CPU cores to 8) does not always double performance.
- Drawback: Monolithic systems are costly, and their scalability is inherently limited.
Distributed Systems: Scaling Horizontally
A distributed system consists of a cluster of interconnected machines (nodes), each with its own resources. Together, they act as a unified computing environment.
- Horizontal Scaling: Instead of upgrading a single system, more nodes are added to the cluster to handle increased workloads.
- Example: A 5-node cluster, where each node has 4 CPU cores, 8 GB of RAM, and 1 TB of storage, collectively provides significant computing power.
Distributed systems are designed to handle the demands of Big Data by leveraging the combined resources of multiple machines. They offer scalability, fault tolerance, and cost efficiency, making them indispensable in modern data processing.
Key Takeaways
- Big Data Characteristics: Volume, Variety, Velocity, Veracity, and Value are the key features that define Big Data.
- Limitations of Traditional Systems: Monolithic systems lack the scalability and efficiency required for managing vast datasets.
- Adoption of Distributed Systems: Distributed architectures, with their horizontal scaling capabilities, enable efficient processing and storage of Big Data.
As the world continues to generate data at an exponential rate, the shift toward distributed systems becomes not just an advantage but a necessity for businesses aiming to remain competitive.
Big Data is transforming industries, offering unparalleled insights and opportunities. Understanding its core characteristics and leveraging the right technological framework is crucial for harnessing its potential. As traditional systems reach their limits, distributed architectures pave the way for a scalable and robust future in data processing.
Whether you’re analyzing social media trends, optimizing supply chains, or making real-time business decisions, mastering Big Data technologies is the key to thriving in a data-driven world.

