
Apache Spark is a powerful open-source distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. In this blog, we’ll dive deep into the architecture of Spark, exploring its components, interactions, and how it leverages resources for efficient computation.
1. Introduction to Spark
Apache Spark is designed to process large datasets quickly and efficiently. It achieves this by distributing data and computations across multiple nodes in a cluster. Spark’s architecture is built around the concept of Resilient Distributed Datasets (RDDs), which are immutable collections of objects that can be processed in parallel.
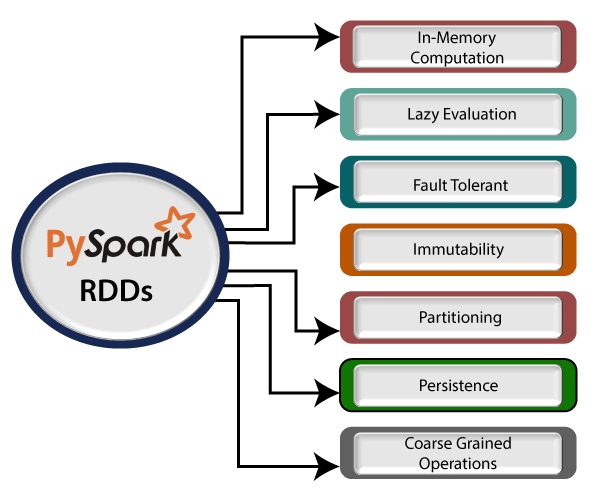
2. Spark Cluster Architecture
A Spark cluster consists of a Master Node and multiple Worker Nodes. The Master Node is responsible for resource management and task scheduling, while the Worker Nodes perform the actual computation.
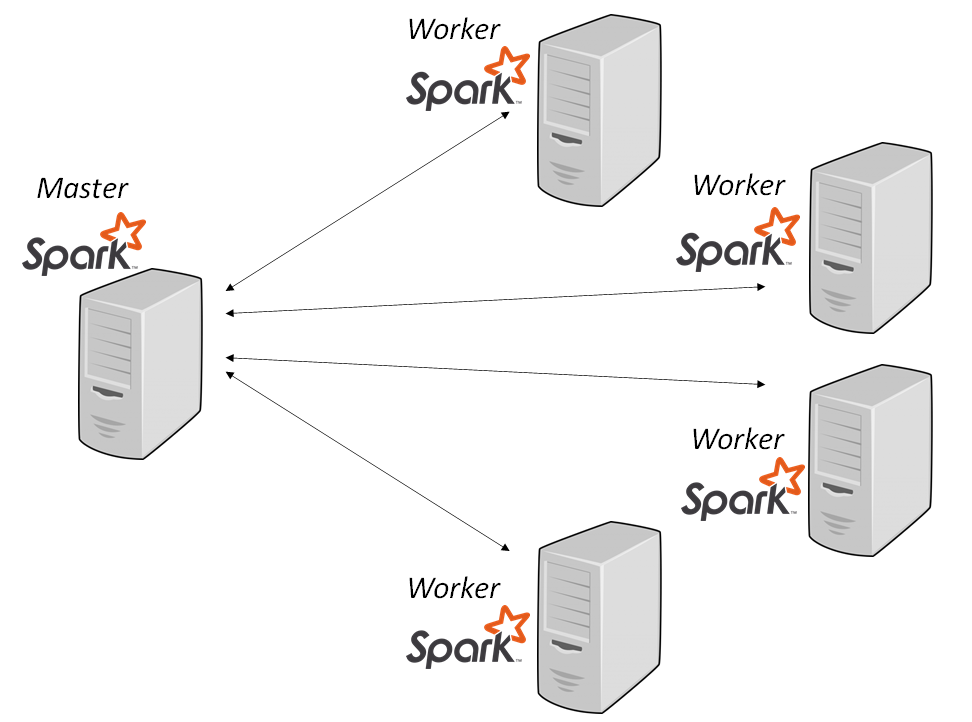
Master Node
The Master Node runs the Cluster Manager, which can be one of the following:
- Standalone: Spark’s built-in cluster manager.
- YARN (Yet Another Resource Negotiator): A resource manager for Hadoop clusters.
- Mesos: A cluster manager that can run Hadoop, Spark, and other applications.
Worker Nodes
Worker Nodes are the machines that execute tasks assigned by the Master Node. Each Worker Node runs an Executor, which is responsible for executing a subset of tasks and storing data in memory or disk.
Resources
In a typical Spark cluster, resources are allocated as follows:
- Cores: The number of CPU cores available for computation.
- Memory: The amount of RAM available for storing data and executing tasks.
For example, a cluster might have 200 cores and 1TB of RAM, with each Worker Node having 100GB of RAM.
3. Spark Application Architecture
A Spark application consists of a Driver Program and multiple Executors.
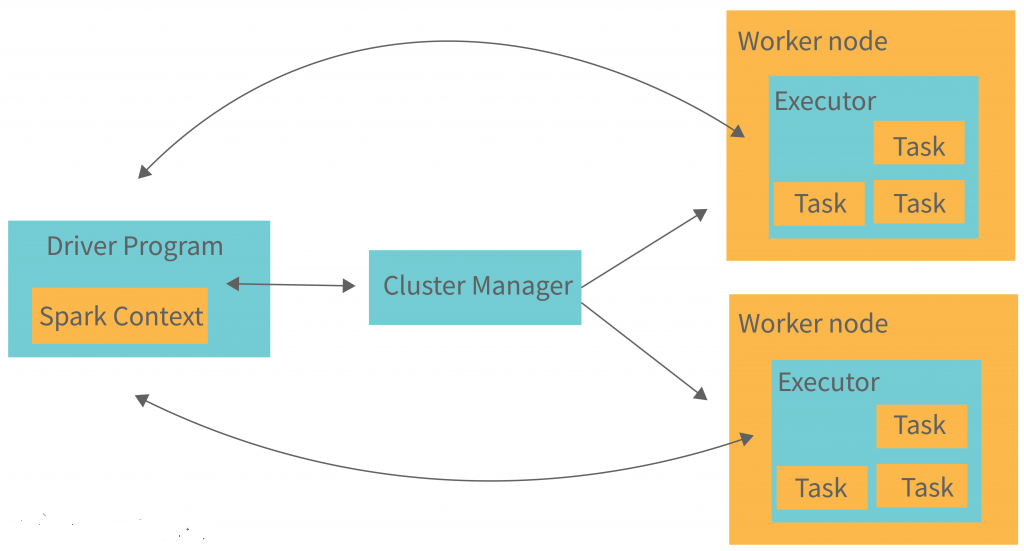
Driver Program
The Driver Program is the main entry point of a Spark application. It defines the application’s logic and coordinates the execution of tasks. The Driver Program runs on the Master Node and performs the following functions:
- Creating RDDs: The Driver Program creates RDDs from input data.
- Transformations and Actions: The Driver Program defines transformations (e.g., map, filter) and actions (e.g., reduce, collect) on RDDs.
- Task Scheduling: The Driver Program schedules tasks to be executed on the Worker Nodes.
Executors
Executors are distributed across the Worker Nodes and are responsible for executing tasks and storing data. Each Executor runs in its own JVM (Java Virtual Machine) and performs the following functions:
- Task Execution: Executors execute tasks assigned by the Driver Program.
- Data Storage: Executors store data in memory or disk for efficient access.
For example, a Spark application might have a Driver with 20GB of RAM and five Executors, each with 25GB of RAM and 5 CPU cores.
4. Interaction Between PySpark and JVM
PySpark is the Python API for Spark, allowing users to write Spark applications using Python. PySpark interacts with the JVM to leverage Spark’s core functionalities.
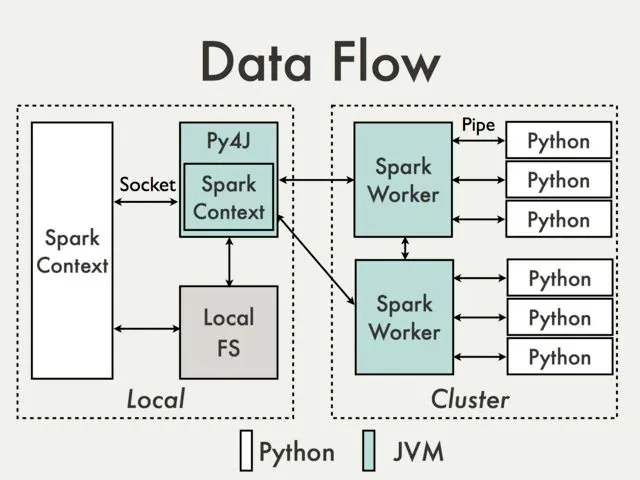
PySpark Driver
The PySpark Driver is the main function of a PySpark application. It interacts with the JVM’s main function, which acts as the Application Driver.
Language Wrappers
PySpark uses language wrappers to interact with the JVM:
- Python: PySpark
- Java/Scala: JVM main function
Spark Core
Spark Core is the underlying engine that provides the basic functionalities of Spark, such as task scheduling, memory management, and fault recovery. It interacts with both the Java wrapper and the Python wrapper.
5. Application Master and Executors
In a distributed computing environment, the Application Master manages the execution of an application. It runs within a JVM and coordinates tasks across multiple Executors.
Application Master
The Application Master is the central component that manages the application’s execution. It communicates with the Executors to manage and coordinate tasks.
Executors
Executors are distributed across the Worker Nodes and run in their own JVMs. Each Executor has a Python worker that interacts with the PySpark Driver.
Apache Spark’s architecture is designed to provide efficient and fault-tolerant distributed computing. By leveraging the power of RDDs, Executors, and the JVM, Spark can process large datasets quickly and efficiently. Understanding the architecture of Spark is crucial for optimizing performance and making the most of its capabilities.

