
In the world of big data, speed and efficiency are paramount. Apache Spark, a general-purpose in-memory compute engine, has emerged as a powerful tool for processing large datasets quickly and with less coding effort compared to traditional MapReduce frameworks.

What is Apache Spark?
Apache Spark is a high-performance, in-memory compute engine designed to handle big data workloads efficiently. Unlike traditional MapReduce, which can be slow and requires significant coding effort, Spark processes data in memory, making it 10x to 100x faster.
Is Apache Spark a Replacement for Hadoop?
No, Apache Spark is not a complete replacement for Hadoop but rather a complementary tool. Here’s why:
Hadoop Components:
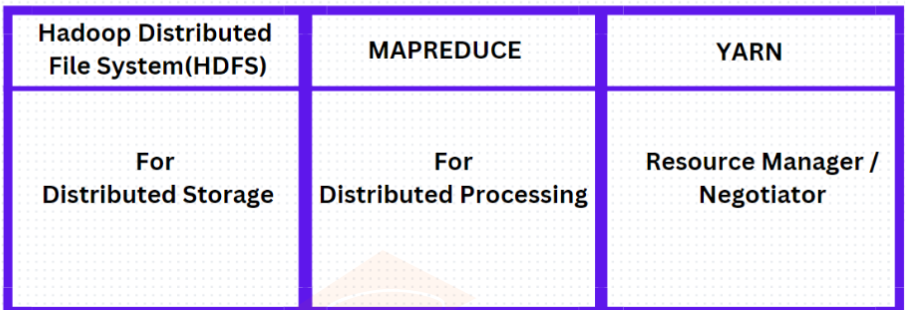
- Storage: Handled by Hadoop Distributed File System (HDFS).
- Compute: Handled by MapReduce.
- Resource Management: Managed by YARN (Yet Another Resource Negotiator).
Spark acts as a replacement for the MapReduce component, not Hadoop as a whole. It is a plug-and-play compute engine that can work with various storage and resource management systems, such as:
- Storage: HDFS, Amazon S3, Azure ADLS Gen2, Google Cloud Storage, or even local storage.
- Resource Managers: YARN, Mesos, Kubernetes, etc.
Why is Spark Faster than Traditional MapReduce?
Spark is significantly faster because it processes data in memory. Traditional MapReduce reads and writes intermediate results to disk, which slows down computation. Spark minimizes these disk I/O operations by retaining intermediate data in memory, resulting in faster data processing.
Spark Programming Languages
Developers can write Spark applications using the following languages:
- Python (PySpark)
- Scala (Spark’s native language)
- Java
- R
Code Example: Word Count Using PySpark
The word count example is a classic demonstration of big data processing. Below is a Python implementation using PySpark:
from pyspark import SparkContext
# Initialize Spark Context
sc = SparkContext("local", "WordCount")
# Load the input file
input_file = "example.txt" # Replace with your file path
text_file = sc.textFile(input_file)
# Perform word count
word_counts = (
text_file.flatMap(lambda line: line.split()) # Split each line into words
.map(lambda word: (word, 1)) # Map each word to a tuple (word, 1)
.reduceByKey(lambda a, b: a + b) # Reduce by key to count occurrences
)
# Save the output
word_counts.saveAsTextFile("output_word_count") # Replace with your desired output path
# Print results (for debugging purposes)
for word, count in word_counts.collect():
print(f"{word}: {count}")Code Breakdown
- Initialize Spark Context:
SparkContextis the entry point for any Spark application. - Load Input File:
ThetextFile()method loads a text file into an RDD (Resilient Distributed Dataset). - Transformations:
flatMap: Splits each line into words.map: Maps each word to a tuple(word, 1).reduceByKey: Aggregates the count of each word.
- Save Results:
ThesaveAsTextFile()method saves the results to a specified directory. - Collect and Print:
Thecollect()method retrieves the results to the driver for debugging or inspection.
Apache Spark simplifies and accelerates big data processing by leveraging in-memory computation and a versatile programming interface. Whether you’re working with HDFS, S3, or local storage, and managing resources via YARN, Mesos, or Kubernetes, Spark’s plug-and-play architecture ensures flexibility and performance.
By supporting multiple languages like Python (PySpark), Scala, Java, and R, Spark empowers developers to efficiently tackle complex data challenges in the language they’re most comfortable with.
You can refer to Spark Architecture.
You might be interested in learning about Hadoop.

