
Introduction
AWS provides a broad range of services for handling big data and real-time streaming workloads. Two of the most commonly used services are Amazon EMR (Elastic MapReduce) and Amazon Kinesis Data Firehose. While both services are designed for processing large-scale data, they cater to different use cases. Understanding their differences is crucial for designing an optimal data pipeline.
In this blog, we will compare AWS EMR and Kinesis Data Firehose based on their functionalities, architectures, and best use cases.
What is AWS EMR?

Amazon EMR is a cloud-based big data processing service that allows users to run distributed processing frameworks like Apache Hadoop, Apache Spark, Apache Hive, and Presto. It is designed for large-scale data processing and is commonly used for batch processing, data transformations, and machine learning workloads.
Key Features of AWS EMR:
- Managed Cluster: Simplifies setup and management of Hadoop and Spark clusters.
- Scalability: Can process petabytes of data using a distributed computing model.
- Supports Multiple Frameworks: Works with Spark, Hive, Presto, HBase, Flink, and others.
- Integration with AWS Services: Works with S3, RDS, DynamoDB, and Redshift for data storage and analytics.
- Customizable Cluster Configuration: Users can configure EC2 instances, networking, and storage as per their needs.
Common Use Cases for AWS EMR:
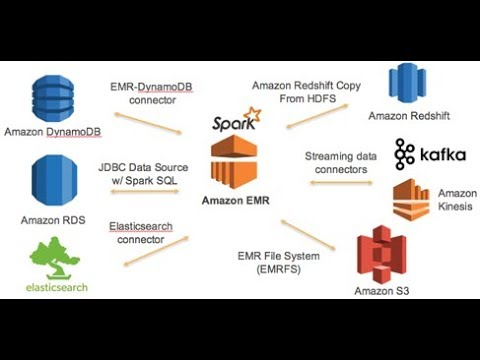
- Big Data Processing & ETL Pipelines: Transforming and aggregating large datasets from multiple sources before storing them in a data warehouse (e.g., Amazon Redshift or S3).
- Machine Learning (ML) Workloads: Running large-scale ML algorithms using Spark MLlib.
- Log Analysis: Processing and analyzing log data from servers, applications, and cloud services.
- Data Lake Analytics: Querying structured and unstructured data stored in Amazon S3 using Apache Spark or Presto.
What is AWS Kinesis Data Firehose?
Amazon Kinesis Data Firehose is a fully managed service for real-time streaming data ingestion and delivery. It enables users to capture, process, and load streaming data into AWS services like Amazon S3, Redshift, OpenSearch Service, and Splunk.
Key Features of AWS Kinesis Data Firehose:
- Real-Time Data Ingestion: Automatically collects and processes streaming data in near real-time.
- Serverless & Managed: No need to provision or manage infrastructure.
- Automatic Batching & Compression: Reduces storage costs and increases efficiency.
- Supports Data Transformation: AWS Lambda integration allows real-time data transformation before storage.
- Scales Automatically: Handles high-throughput streaming data without manual intervention.
Common Use Cases for AWS Kinesis Data Firehose:
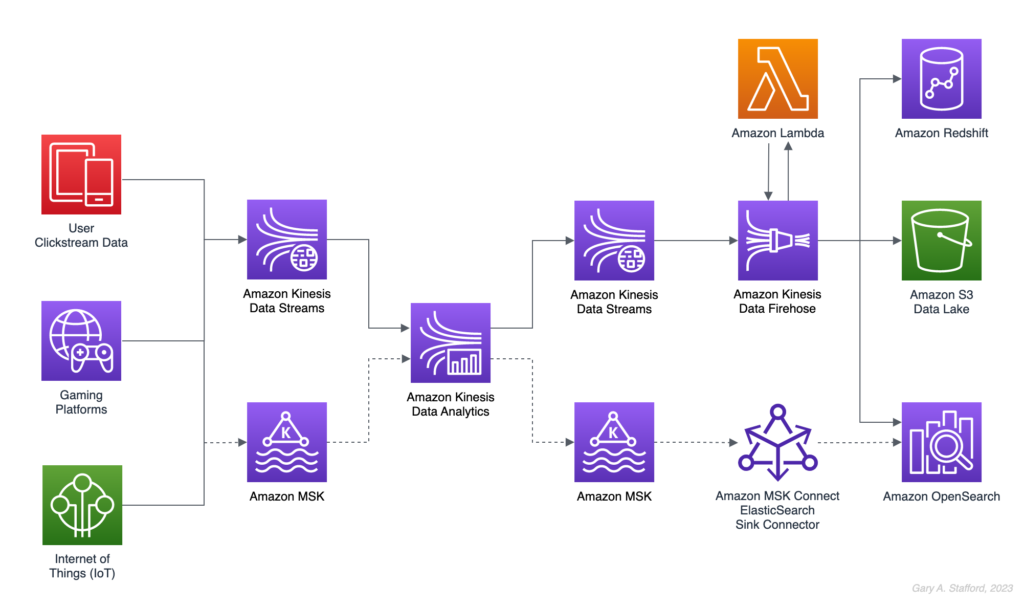
- Real-Time Log & Event Streaming: Streaming logs from EC2 instances, VPC Flow Logs, and CloudTrail to S3 or OpenSearch.
- IoT Data Processing: Collecting sensor data from IoT devices for real-time monitoring and analytics.
- Clickstream & User Behavior Analysis: Capturing user interactions from web and mobile apps in real-time.
- Streaming Data to Redshift: Ingesting large volumes of structured data directly into Amazon Redshift for analytics.
AWS EMR vs. AWS Kinesis Data Firehose: A Comparative Analysis
| Feature | AWS EMR | AWS Kinesis Data Firehose |
|---|---|---|
| Processing Type | Batch Processing | Real-Time Streaming |
| Best For | Big data analytics, ETL, machine learning | Log collection, real-time analytics, event streaming |
| Data Sources | S3, RDS, DynamoDB, HDFS | Web apps, IoT devices, AWS CloudWatch, Event logs |
| Output Destinations | S3, Redshift, DynamoDB, On-Prem | S3, Redshift, OpenSearch, Splunk |
| Performance | Optimized for large-scale data processing | Low-latency, continuous streaming |
| Management Overhead | Requires cluster setup and tuning | Fully managed and serverless |
| Cost | Pay per EC2 instance and processing time | Pay per GB ingested and processed |
Choosing Between AWS EMR and AWS Kinesis Data Firehose
Use AWS EMR if:
✅ You need to process large volumes of historical data (batch processing).
✅ You require complex transformations, aggregations, and ML model training.
✅ Your workloads involve structured and unstructured data processing from sources like S3, RDS, or DynamoDB.
✅ You need customizable compute and storage resources for specific performance requirements.
Use AWS Kinesis Data Firehose if:
✅ You need real-time or near real-time data ingestion.
✅ Your use case involves log collection, streaming analytics, or monitoring.
✅ You prefer a fully managed, serverless solution without infrastructure overhead.
✅ You need low-latency data delivery to S3, Redshift, OpenSearch, or Splunk.
Real-World Example Use Cases
Scenario 1: Processing Historical Sales Data
- A retail company wants to analyze sales data stored in Amazon S3.
- They use AWS EMR with Apache Spark to clean, transform, and aggregate the data.
- The processed data is then stored in Amazon Redshift for business intelligence and reporting.
- Best Choice: AWS EMR (Batch processing for large-scale ETL jobs).
Scenario 2: Real-Time Clickstream Analysis
- An e-commerce company wants to track customer behavior in real-time.
- They use Kinesis Data Firehose to collect clickstream data from their web application.
- The data is delivered to Amazon S3 and OpenSearch for real-time analytics.
- Best Choice: AWS Kinesis Data Firehose (Low-latency event streaming and ingestion).
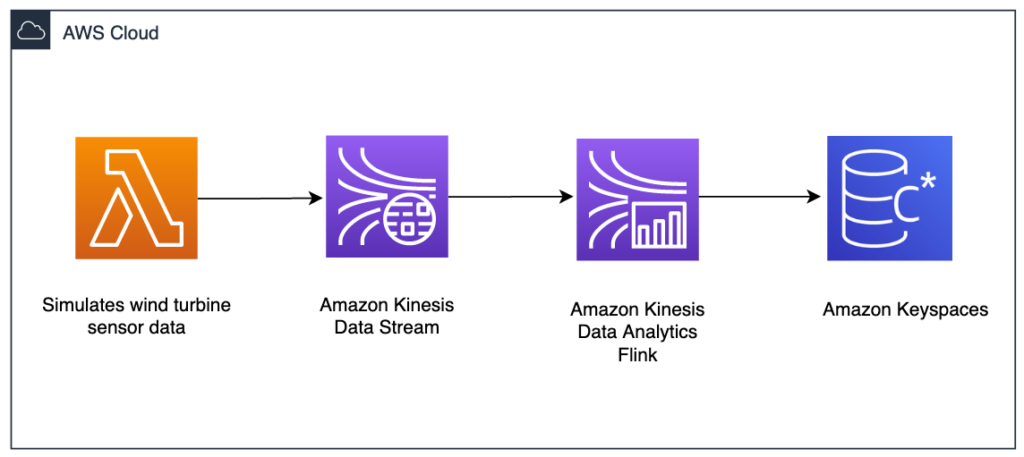
Scenario 3: IoT Sensor Data Processing

- A manufacturing company collects sensor data from IoT devices.
- The data is streamed using AWS Kinesis Data Firehose into Amazon S3 for further analysis.
- They later run periodic machine learning models on AWS EMR to predict equipment failures.
- Best Choice: Kinesis for real-time ingestion + EMR for batch processing ML models.
AWS EMR and Kinesis Data Firehose are powerful services but serve different purposes.
- Use AWS EMR for large-scale batch data processing and analytics.
- Use AWS Kinesis Data Firehose for real-time streaming ingestion and analytics.
- In some architectures, both services can be used together—Kinesis for real-time data capture and EMR for in-depth historical analysis.
By understanding your data processing requirements—batch vs. real-time, structured vs. unstructured, analytics vs. ML—you can choose the right AWS service to build an efficient and scalable data pipeline.

