
In the realm of data engineering, a well-designed data pipeline is fundamental for extracting, transforming, and loading (ETL) data across systems. This blog delves into the technical aspects of designing data pipelines, key considerations, best practices, and tools to create scalable and efficient solutions.
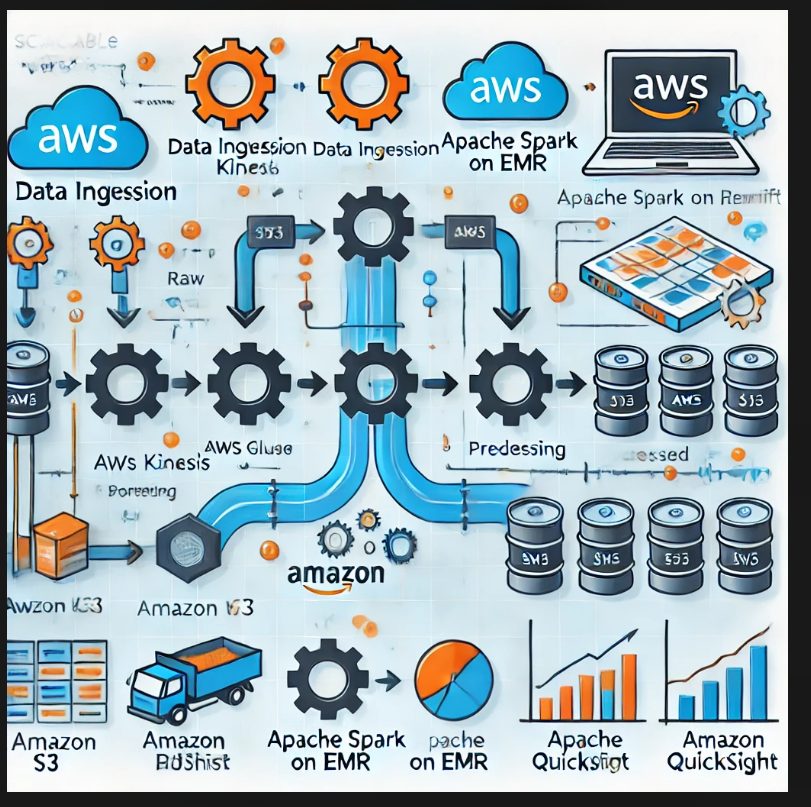
Key Components of a Data Pipeline
- Data Ingestion
Data ingestion involves collecting data from various sources, such as APIs, databases, flat files, or streaming platforms like Kafka. Depending on the source type and latency requirements, ingestion methods can be batch, real-time, or hybrid. - Data Processing
Batch Processing: Useful for large datasets processed at scheduled intervals.
Stream Processing: Ideal for real-time data processing where low latency is crucial.
Tools like Apache Beam, Spark, or AWS Glue simplify this step by offering ETL and transformation capabilities.
- Data Storage
Choose storage solutions based on the type of data and access patterns.
Examples: Amazon S3 for unstructured data, Redshift for analytical queries, or DynamoDB for NoSQL needs.
Ensure your storage layer supports scalability, durability, and cost efficiency.
- Data Visualization
Visualizing data involves tools like Tableau, Power BI, or Amazon QuickSight, enabling stakeholders to make informed decisions. Integrating visualization into pipelines often requires query-optimized data models.
Key Design Considerations
- Scalability
Design pipelines that can scale with data volume and traffic spikes.
Use serverless options like AWS Lambda or Google Cloud Functions to handle event-driven loads.
- Flexibility
Modularize components to allow independent updates or replacements.
Employ APIs and open formats (e.g., JSON, Avro, or Parquet) to avoid vendor lock-in.
- Reliability
Build fault-tolerant systems with retry mechanisms.
Monitor failures and ensure idempotency in operations to avoid duplicate data.
- Security
Encrypt data at rest and in transit using standards like AES-256.
Implement IAM roles, VPCs, and audit logging for strict access control.
- Data Quality
Employ tools like AWS Glue DataBrew or Great Expectations to validate data quality.
Use versioning for schema changes and monitor anomalies.
Best Practices
- Modular Architecture
A modular approach simplifies debugging and enhances the maintainability of pipelines. For example, separate ingestion, processing, and storage layers into distinct modules. - Leverage Cloud Services
Cloud-native services like AWS Glue, Google Cloud Dataflow, or Azure Data Factory reduce operational overhead and provide out-of-the-box scaling and monitoring capabilities. - Data Lineage and Metadata
Enable data lineage to trace transformations and sources, ensuring compliance and easier debugging. Tools like Apache Atlas or AWS Lake Formation can help. - Monitoring and Logging
Use tools like Apache Airflow for orchestration, Grafana or Prometheus for real-time monitoring, and AWS CloudWatch or Google Cloud Logging for detailed activity logs. - Testing and Validation
Automate testing for data integrity and transformations. Validate pipelines using simulated data flows before moving to production.
Recommended Tools and Technologies
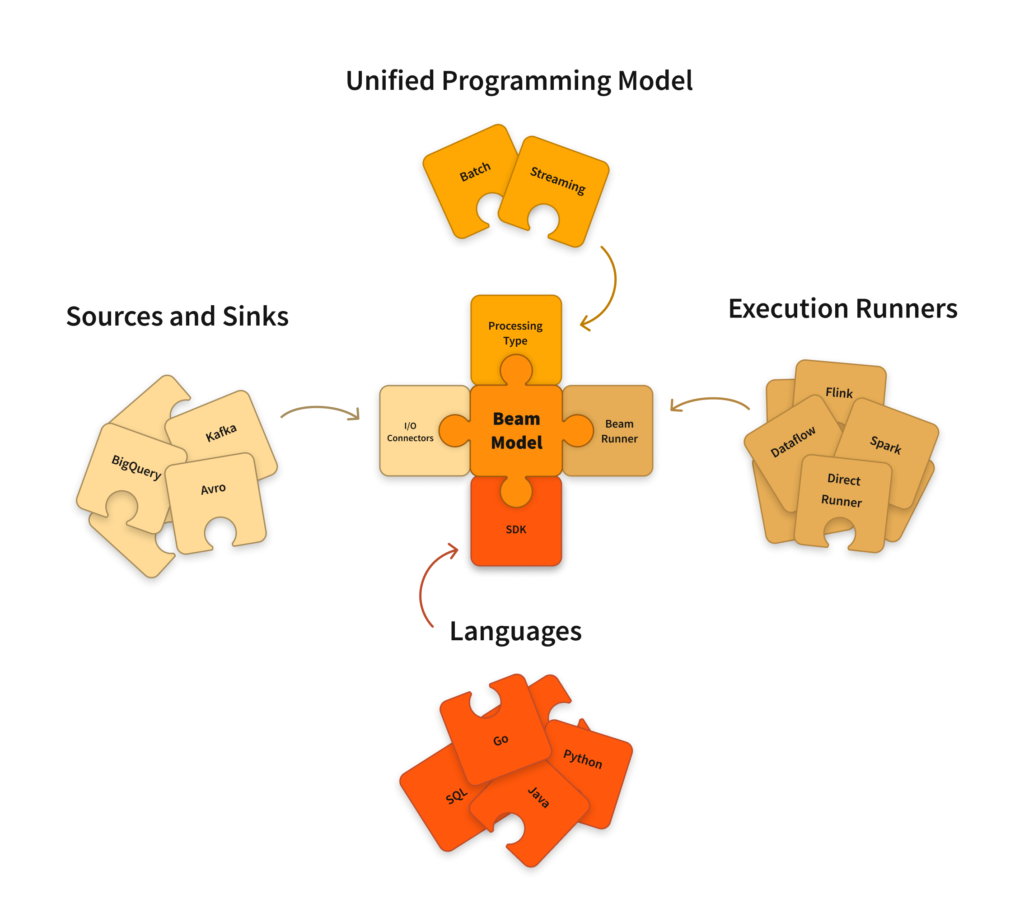
- Apache Beam: Unified programming model for batch and streaming pipelines.
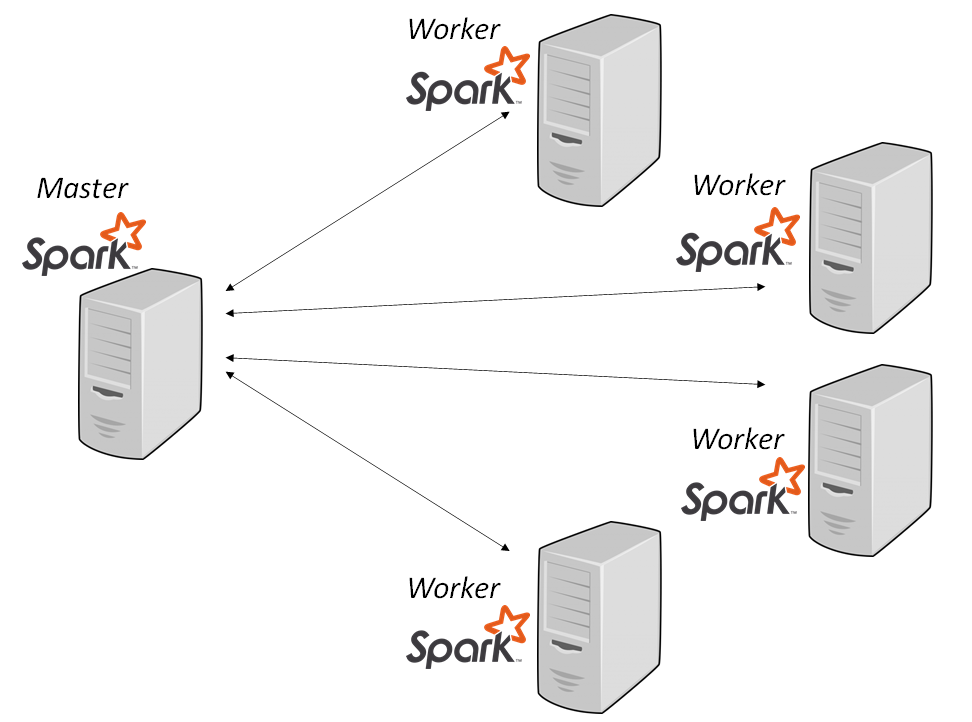
- Apache Spark: Efficient in-memory data processing, ideal for large-scale analytics.
- Apache Airflow: Workflow orchestration for scheduling and monitoring tasks.

- AWS Glue: Managed ETL service with built-in support for schema discovery and metadata.

- Google Cloud Dataflow: Managed stream and batch data processing service with autoscaling capabilities.

Example Architecture
For a robust and scalable data pipeline:
Ingestion: Use Amazon Kinesis for real-time data ingestion.
Processing: Process data in AWS Glue or Apache Spark on EMR.
Storage: Store raw data in Amazon S3, processed data in Redshift, and metadata in DynamoDB.
Visualization: Use Amazon QuickSight for building dashboards and sharing insights.
Building a high-performing data pipeline requires thoughtful planning and a solid understanding of your data’s nature and flow. By leveraging modern tools and adhering to best practices, you can design pipelines that are scalable, reliable, and secure—enabling your organization to unlock the true potential of its data.

