
In the ever-evolving world of data management, choosing the right system for storing, processing, and analyzing data is critical. Each system—Database, Data Warehouse, Data Lake, and the hybrid Data Lakehouse—serves distinct purposes and use cases. This blog will dive into each, explaining their features, advantages, challenges, and examples.
1. Databases

A database is the backbone of modern applications, designed to manage and process day-to-day transactional data efficiently.
Key Features:
- Purpose: Primarily used for Online Transactional Processing (OLTP), where speed and accuracy are paramount.
- Data Type: Works with structured data, typically organized into rows and columns.
- Schema: Follows Schema on Write, meaning data must conform to a predefined schema before being stored.
Advantages:
- Optimized for frequent, real-time transactions.
- Reliable and robust for critical applications such as banking or e-commerce.
Challenges:
- Not suited for analytical tasks or storing large volumes of historical data.
- High storage costs for maintaining large datasets.
Examples:
- Oracle Database, MySQL, PostgreSQL.
- Use Case: Online banking systems where transactional integrity is critical.
2. Data Warehouses (DWH)
A Data Warehouse is tailored for analytical tasks, providing deep insights by processing large volumes of historical data.
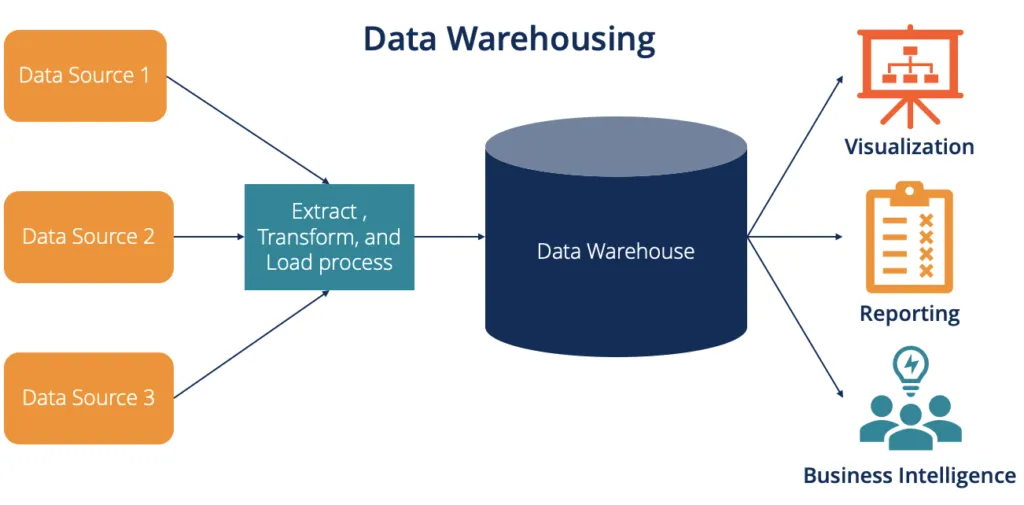
Key Features:
- Purpose: Designed for Online Analytical Processing (OLAP), supporting complex queries for business intelligence and reporting.
- Data Type: Handles structured data collected from various sources.
- Schema: Employs Schema on Write, ensuring data consistency during ingestion.
- ETL Process:
- Extract: Gather data from source systems.
- Transform: Clean, aggregate, and reformat data.
- Load: Store transformed data in the warehouse.
Advantages:
- Excellent for generating insights from historical data.
- Supports complex queries and data modeling for decision-making.
Challenges:
- Transforming data before loading is time-consuming and reduces flexibility.
- High storage costs, though lower than traditional databases.
Examples:
- Teradata, Amazon Redshift, Google BigQuery.
- Use Case: Retail companies analyzing sales trends over years to predict demand.
3. Data Lakes
A Data Lake is a flexible, cost-effective repository for storing vast amounts of raw data in various formats.
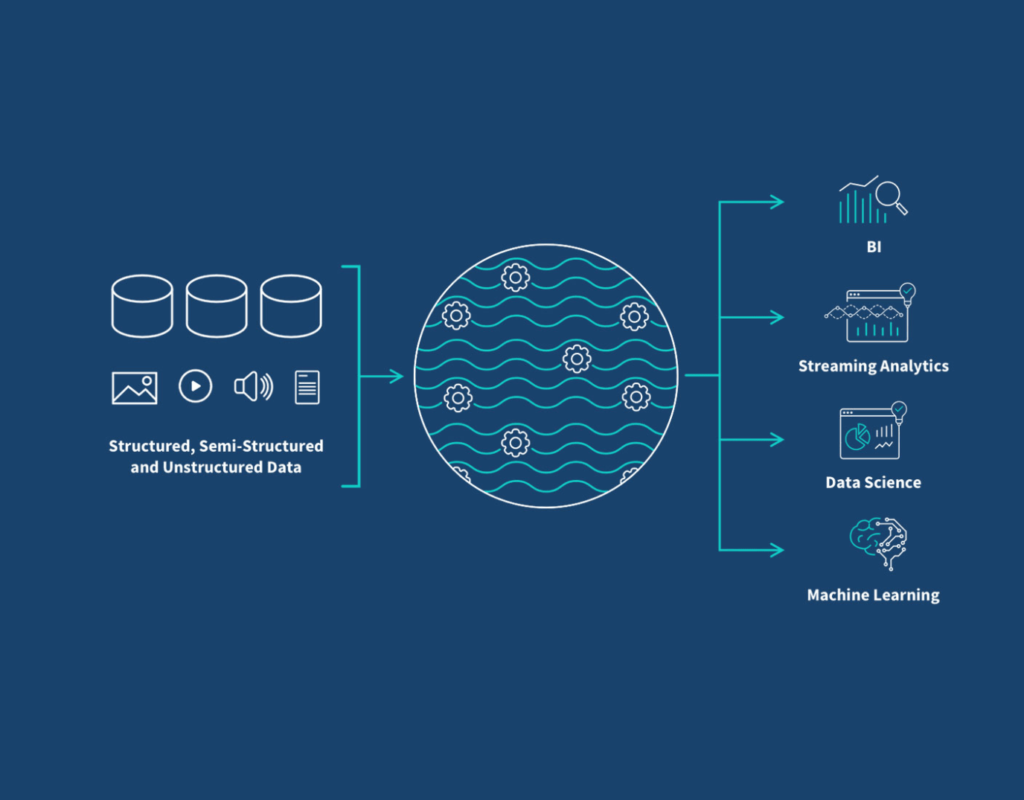
Key Features:
- Purpose: Facilitates storing and analyzing structured, semi-structured, and unstructured data.
- Data Type: Accommodates raw data, such as log files, videos, and CSVs.
- Schema: Utilizes Schema on Read, where a schema is applied only when the data is accessed.
- ELT Process:
- Extract: Collect data from diverse sources.
- Load: Store data in its original, raw form.
- Transform: Apply transformations only as needed during analysis.
Advantages:
- Low storage costs, enabling storage of years of historical data.
- Greater flexibility by deferring transformations until analysis is required.
Challenges:
- Query performance may be slower compared to structured systems.
- Requires expertise to handle and analyze raw data effectively.
Examples:
- Amazon S3, HDFS (Hadoop Distributed File System).
- Use Case: Streaming platforms storing raw user interaction data for later analysis.
4. Data Lakehouses
The Data Lakehouse combines the best features of Data Lakes and Data Warehouses into a single, unified system.

Key Features:
- Purpose: Streamlines the process of managing and analyzing large datasets while supporting diverse data formats.
- Hybrid Architecture:
- Inherits flexibility and cost-effectiveness from Data Lakes.
- Provides structure, schema enforcement, and performance optimizations like Data Warehouses.
- Schema: Supports both Schema on Write and Schema on Read, depending on the data use case.
Advantages:
- Eliminates the need for separate systems for raw and structured data.
- Reduces the complexity and time involved in transferring data between lakes and warehouses.
- Ideal for diverse workloads, including machine learning and advanced analytics.
Examples:
- Databricks Lakehouse Platform, Microsoft Fabric.
- Use Case: Businesses running predictive models on both raw and processed data to gain insights in real time.
Comparison Table
| Feature | Database | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|---|
| Purpose | Transactions (OLTP) | Analytics (OLAP) | Flexible data storage | Unified analytics |
| Data Type | Structured | Structured | Structured + Unstructured | Structured + Unstructured |
| Schema | Schema on Write | Schema on Write | Schema on Read | Both |
| Cost | High | Moderate | Low | Moderate |
| Examples | MySQL, Oracle | Teradata, Redshift | HDFS, Amazon S3 | Databricks, Fabric |
Understanding the differences between Databases, Data Warehouses, Data Lakes, and Data Lakehouses is crucial for making informed decisions about data storage and analytics solutions.
- Databases are ideal for transactional systems.
- Data Warehouses power business intelligence with structured data.
- Data Lakes provide cost-effective storage for raw and unstructured data.
- Data Lakehouses bridge the gap, enabling unified data management and analytics.
Choosing the right system depends on your organization’s specific needs, from real-time transaction processing to advanced analytical tasks.

