
What is Hadoop?

Hadoop was one of the first frameworks designed to solve Big Data problems. It’s not just a single tool but a combination of various tools and technologies that work together to process and analyze massive datasets efficiently.
Evolution of Hadoop
- 2007: Introduction of Hadoop 1.0
- 2012: Launch of Hadoop 2.0
- Current Version: Hadoop 3.3 (as of now)
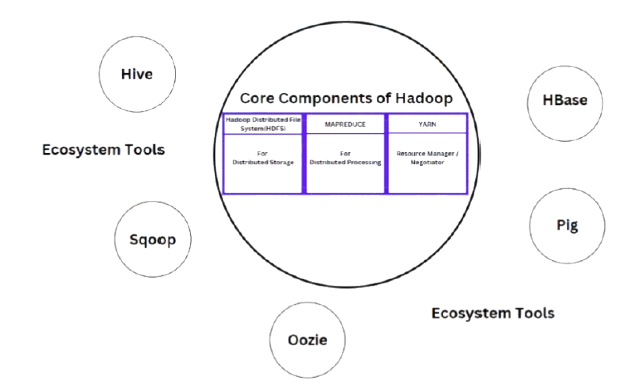
Core Components of Hadoop
Hadoop consists of three primary components:
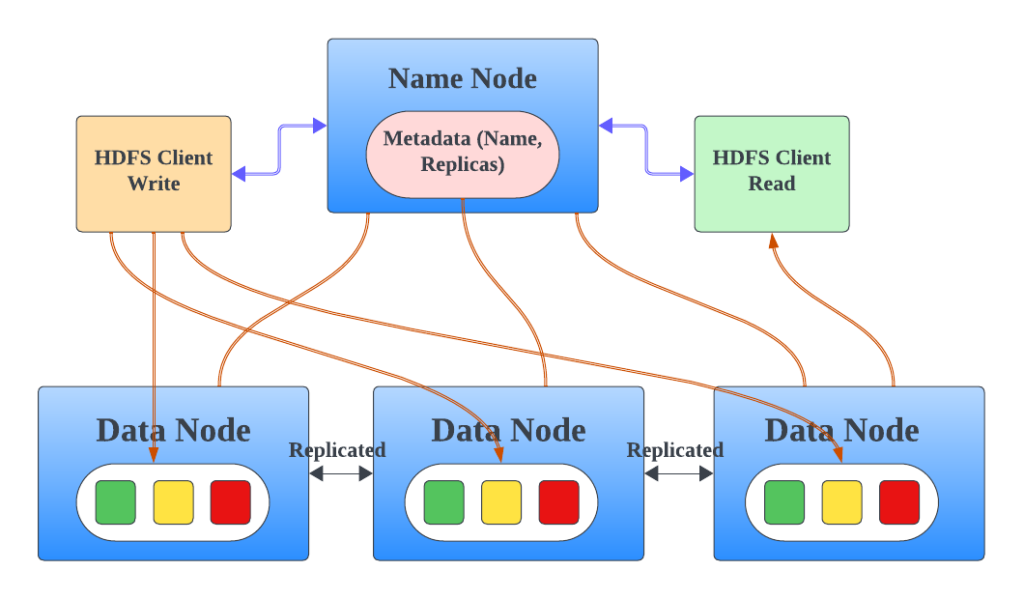
- Hadoop Distributed File System (HDFS):
- HDFS is a distributed storage system where data is divided into blocks and stored across multiple nodes in a cluster.
- It ensures fault tolerance and scalability, enabling large-scale data storage.
- MapReduce:
- MapReduce is a programming model used for distributed data processing.
- It processes data stored in HDFS by dividing tasks into “map” and “reduce” phases.
- However, writing MapReduce code is complex and requires extensive programming in Java, making it less favorable today.
- YARN (Yet Another Resource Negotiator):
- YARN acts as a resource manager for Hadoop clusters.
- For example, if you have a 20-node Hadoop cluster with multiple users requesting resources, YARN allocates resources based on demand.
Limitations of MapReduce
MapReduce, once a core processing model, is now considered obsolete due to:
- Slow processing speed.
- Complexity in writing and maintaining Java-based code.
Hadoop’s Ecosystem Technologies
To address challenges in Hadoop’s core components, several ecosystem tools have been developed:
- Sqoop:
- Used for data movement between relational databases and HDFS.
- For example, if you want to transfer data from MySQL to HDFS, Sqoop simplifies this task.
- Cloud alternative: Azure Data Factory (ADF).
- Pig:
- A scripting language mainly used for data cleaning.
- Pig executes under the hood using MapReduce.
- Hive:
- Provides an SQL-like interface for querying data stored in HDFS.
- Hive abstracts the complexity of MapReduce programming.
- Oozie:
- A workflow scheduler for managing complex jobs.
- For instance, if you need two MapReduce jobs (M1 and M2) to run in parallel, followed by another job (M3), Oozie can handle this workflow.
- Cloud alternative: Azure Data Factory.
- HBase:
- A NoSQL database used for real-time access to data stored in HDFS.
- Ideal for scenarios requiring quick retrieval of specific records.
- Cloud alternative: Cosmos DB.
Challenges with Hadoop
- Complexity of MapReduce:
- Writing MapReduce code is tedious and inefficient for small tasks.
- Steep Learning Curve:
- Each component requires specialized knowledge. For example, Pig for data cleaning, Hive for querying, and so on.
Is Hadoop Still Relevant?
While Hadoop has paved the way for modern Big Data technologies, its role is gradually diminishing:
- HDFS and YARN: These components are still widely used.
- MapReduce: Largely replaced by modern frameworks like Apache Spark.
Real-World Example
Imagine a retail company analyzing customer purchase patterns:
- Data Storage: HDFS stores the transactional data from various stores.
- Data Querying: Hive allows SQL-like querying to find trends, such as the most purchased items.
- Workflow Management: Oozie schedules daily batch jobs to clean data and generate reports.
- Real-Time Analysis: HBase enables instant retrieval of specific customer records during a support call.
Hadoop revolutionized Big Data processing by providing a scalable and fault-tolerant framework. However, with advancements in technology, alternatives like Apache Spark and cloud-based solutions are taking center stage. While components like HDFS and YARN remain valuable, the ecosystem’s complexity has paved the way for more streamlined tools and platforms.
Hadoop’s legacy lives on as the foundation of modern Big Data solutions.
You might also like to know about Apache Spark.

