
Introduction to HDFS: The Backbone of Big Data Storage
In today’s data-driven world, the ability to store, process, and analyze vast amounts of data is essential for businesses, researchers, and developers alike. Apache Hadoop, an open-source framework designed for distributed storage and processing, plays a key role in managing big data. At the heart of Hadoop is the Hadoop Distributed File System (HDFS), a scalable and reliable system designed to handle massive amounts of data across distributed clusters.
In this blog, we will explore the core components of HDFS, how it works, and its crucial role in the Hadoop ecosystem. Whether you’re a beginner or someone with some experience, this guide will provide you with a comprehensive understanding of HDFS.
What is HDFS?
HDFS is the distributed file system used by the Hadoop framework to store large datasets across a cluster of computers. It’s designed to be fault-tolerant, scalable, and high-throughput. The main goal of HDFS is to handle data in a distributed manner, enabling quick access and high reliability even in the event of hardware failures.
Unlike traditional file systems that store data on a single machine, HDFS stores data in blocks across multiple nodes, providing parallel access and redundancy for data safety.
HDFS Architecture: Master-Slave Setup
HDFS follows a master-slave architecture consisting of two major components:

- NameNode (Master Node):
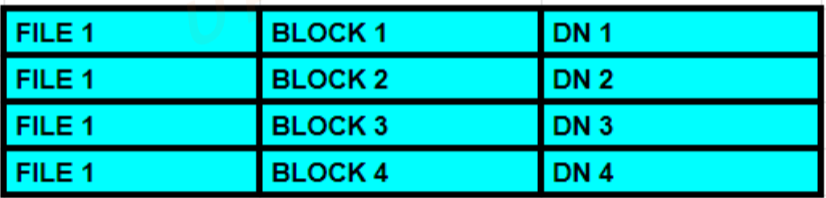
- The NameNode acts as the central management server in HDFS. It is responsible for storing the metadata of the files, such as the file names, directory structure, permissions, and locations of data blocks across the cluster.
- The NameNode does not store the actual data; instead, it keeps track of which blocks of data are stored on which DataNodes.
- DataNode (Slave Nodes):
- The DataNodes are the worker nodes in the Hadoop cluster that actually store the data. These nodes hold the actual data in the form of blocks (default size: 128MB) and handle read and write requests from clients.
- DataNodes regularly send heartbeat signals to the NameNode to let it know they are alive. If a DataNode fails, the NameNode replicates the data stored on it to ensure data availability.
How Data is Stored in HDFS
When you store data in HDFS, it is divided into fixed-size blocks. The default block size in recent Hadoop versions is 128MB, but this can be adjusted depending on the specific needs of the application.
Step-by-Step Process of Storing Data:
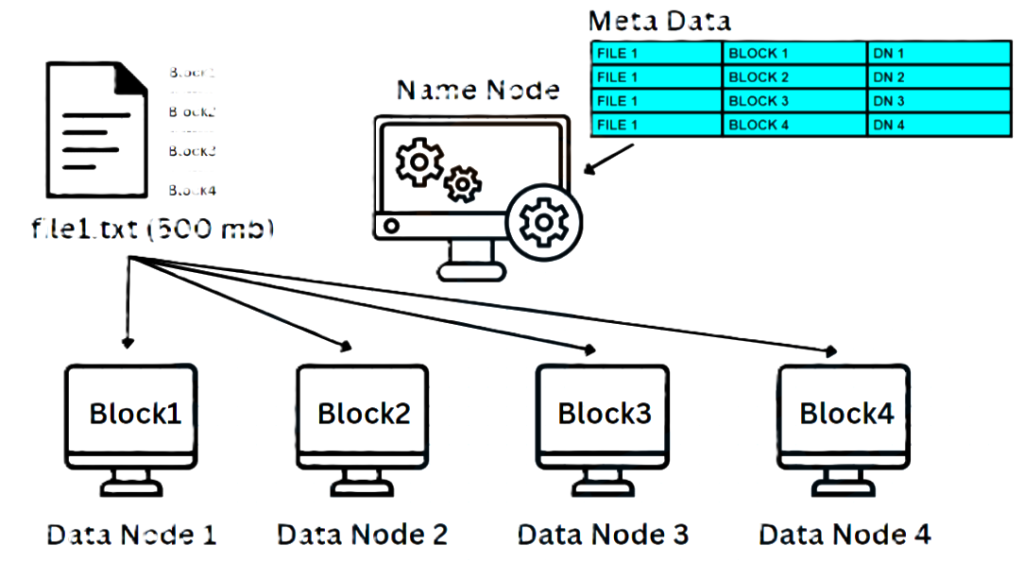
- File Division: A file (e.g., 500MB) is divided into smaller blocks (128MB each).
- Example: A 500MB file might be split into 4 blocks: 3 blocks of 128MB and 1 block of 116MB.
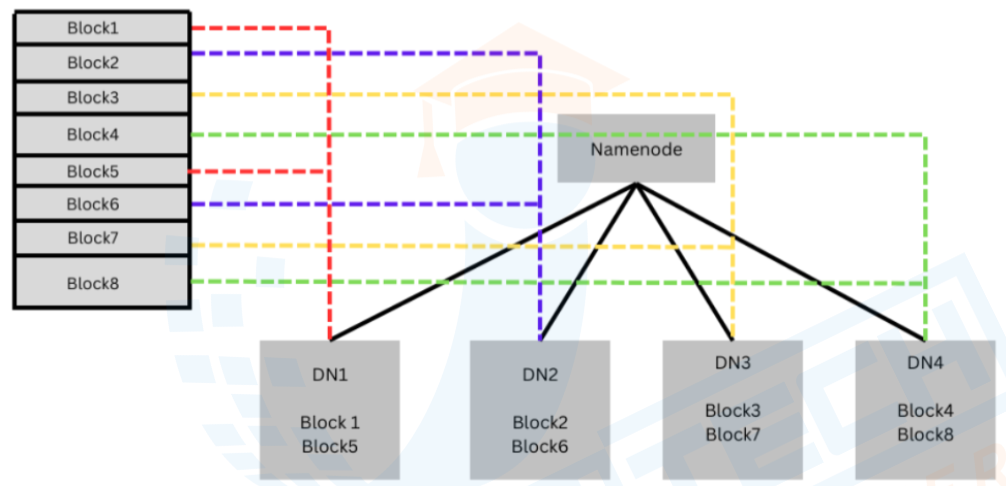
- Block Replication: These blocks are replicated to multiple DataNodes. The default replication factor is 3, meaning each block will have three copies on different DataNodes.
- Metadata Management: The NameNode stores the metadata about where the blocks are located on the cluster but does not store the actual data.
- DataNode Storage: DataNodes store the actual blocks on their local disks and serve data to clients when requested.
Client Requests in HDFS
When a client wants to read a file from HDFS, the following steps occur:
- The client sends a request to the NameNode.
- The NameNode checks its metadata to determine the locations of the file’s blocks.
- The NameNode responds with the locations of the blocks.
- The client then contacts the relevant DataNodes directly to retrieve the blocks.
This process ensures that data can be retrieved efficiently in parallel from multiple nodes, improving the overall speed and performance of data access.
Fault Tolerance in HDFS
One of the main advantages of HDFS is its fault tolerance. Since it is a distributed system, there is always a risk of hardware failure. HDFS handles this through data replication.
How HDFS Ensures Fault Tolerance:
- DataNode Failure: If a DataNode fails, HDFS ensures that the lost data is replicated from another DataNode that holds a replica. The replication factor (default: 3) ensures that multiple copies of data exist across different nodes.
- NameNode Failure: The NameNode is critical to the operation of HDFS, and if it fails, the entire system could be compromised. However, to mitigate this risk, HDFS can use a Secondary NameNode or NameNode Federation to back up the metadata and provide failover capabilities.
Why HDFS Uses Large Block Sizes
HDFS is optimized for high-throughput data access rather than low-latency access. The default block size of 128MB strikes a balance between performance and efficiency. Here’s why:
- Smaller Block Size: If the block size is smaller than 128MB, the number of blocks increases, which leads to more overhead on the NameNode as it has to manage more metadata entries. Although it increases parallelism, it can overburden the NameNode.
- Larger Block Size: On the other hand, a larger block size (greater than 128MB) reduces the number of blocks and metadata, making the NameNode less burdened. However, it may compromise parallelism, as fewer blocks are available to process in parallel.
Thus, a 128MB block size is the most balanced and commonly used setting for Hadoop clusters.
Rack Awareness and Data Distribution

HDFS also incorporates rack awareness to enhance fault tolerance. A rack refers to a group of machines located in a data center or physical location. The data is distributed across different racks to ensure high availability.
- Replication Across Racks: By default, HDFS stores replicas of each block on different racks. This ensures that in the event of a rack failure (e.g., network failure, power loss), data remains accessible from other racks.
Why HDFS is Essential for Big Data Storage
HDFS is a powerful distributed file system designed to meet the demands of big data. Its master-slave architecture, block-based storage, fault tolerance, and scalability make it an ideal choice for storing large volumes of data across distributed systems. By providing high throughput, scalability, and fault tolerance, HDFS ensures that data can be stored and accessed efficiently, even in the face of hardware failures.
Understanding how HDFS works will give you valuable insights into the foundation of Hadoop and its ability to handle massive data workloads. As organizations increasingly rely on big data, mastering HDFS is crucial for anyone working in data engineering or data science.

